
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- OOP
- beautifulsoup
- CSS
- github
- body
- flaskframework
- mysql
- javascript
- java
- POST
- synology
- Algorithm
- backend
- atlas
- requests
- mongodb
- pymongo
- get
- Crawling
- PYTHON
- json
- openapi
- frontend
- portfolio
- CRUD
- fetch
- NAS
- Project
- flask
- venv
- Today
- Total
wisePocket
[Python] "Genie" 지니 음악 차트 데이터 크롤링 실습 본문
[Python] "Genie" 지니 음악 차트 데이터 크롤링 실습
ohnyong 2023. 7. 7. 16:07현재까지 배운 내용들로
웹 크롤링 하기 실습을 최대한 안보고 진행해보자.
Genie라는 음악 스트리밍 서비스에서 실시간, 일간, 주간, 월간 등 다양한 랭킹 차트를 제공한다.
그 중 가장 최근인 2023년 6월 월간 음악 랭킹 차트를 크롤링하고
- URL = https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230601
- "순위 / 곡 제목 / 가수"
데이터를 가져오는 것을 실습하고자 한다.
0. 라이브러리 임포트와 HTML 크롤링
웹 크롤링을 위해서 requests를
받아온 html 소스를 parsing(문자열들을 분석/분해/구조화/가공 해주는 프로세스)해줄 수 있는 beautifulsoup을
임포트하면서 시작한다.
# 크롤링 = 웹페이지에서 어떤 데이터를 가져오는것
import requests
from bs4 import BeautifulSoup
URL = "https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230601"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 위 링크 페이지의 전체 HTML이 아웃풋 된다
print(soup)import, requests.get(), BeautifulSoup()
이 실행되고 데이터가 변수에 담기고 옮겨지는 과정에 문제가 없는지 우선 디버깅해준다.
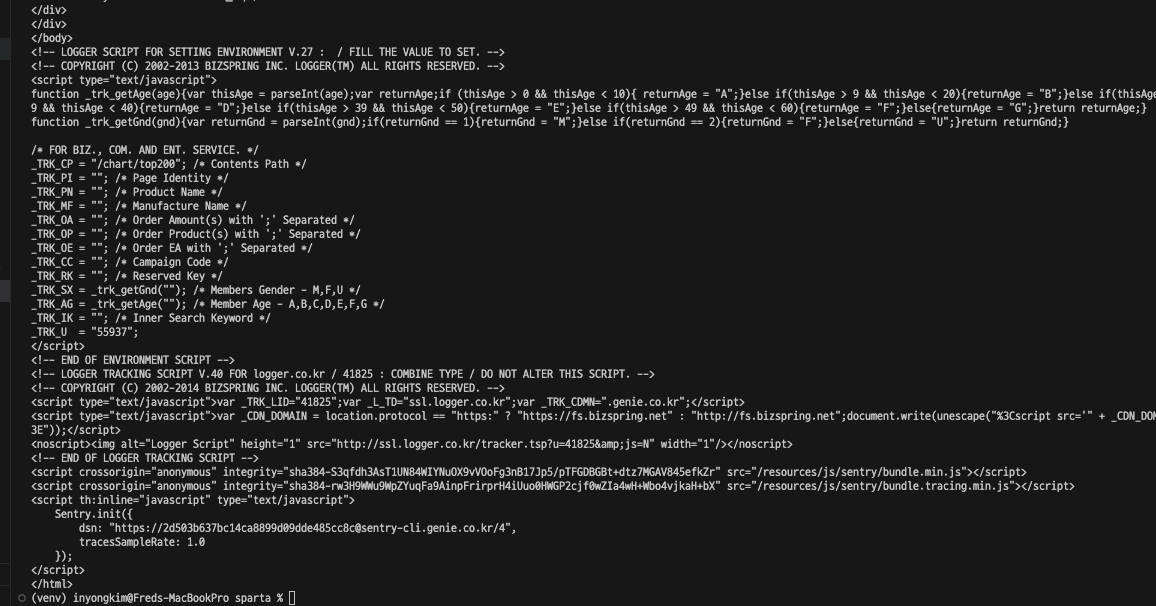
html 소스를 soup이라는 변수에 담아두었다.
*soup에 담긴 html을 보는중 웹 페이지의 소스보기와 비교해서
<body>태그가 닫히는 위치가 다른것을 확인했다. 왜이런 현상이 나타나는걸까?
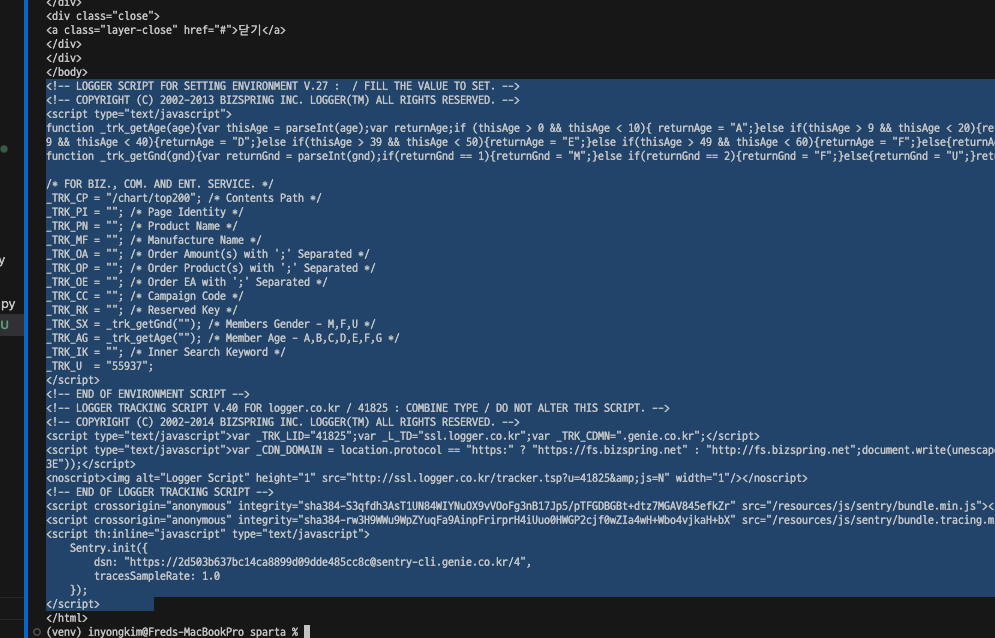

크롤링하는 과정이 웹 페이지의 소스를 그대로 가져오는줄 알았는데
<script> 태그의 위치, 계층 구조가 서로 다르다?
parser의 역할중에 계층 구조를 재배열 해주는 기능도 있는지.. 일단 궁금해서 질문방에 올려놨다.
1. 원하는 데이터 가져오기(1개부터)
내가 필요로하는 첫번째 데이터는 곡의 제목이다.
개발자 도구에서
곡 제목이 위치한 위치까지 계층을 열어보면
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis에 위치하고 있다. 간편하게 해당 블록에서 "Copy selector"를 누르면 대상 계층 경로를 복사해준다.
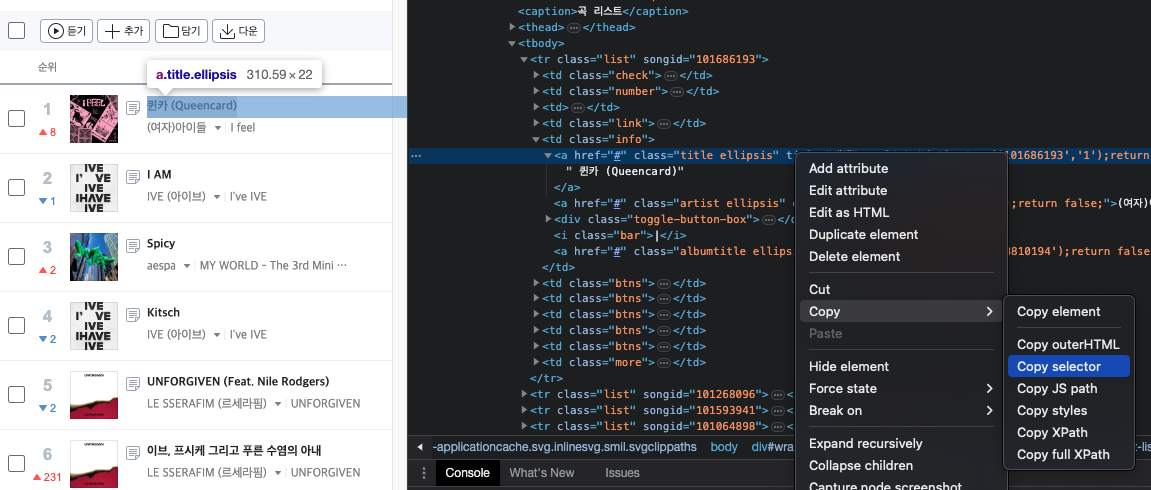
이제 soup.select_one(' .. ')으로 해당 데이터를 찾는지 확인해보자.
데이터 내 이상한 공백이 함께 추출되서 .strip()으로 띄워쓰기를 제거해 주었다.
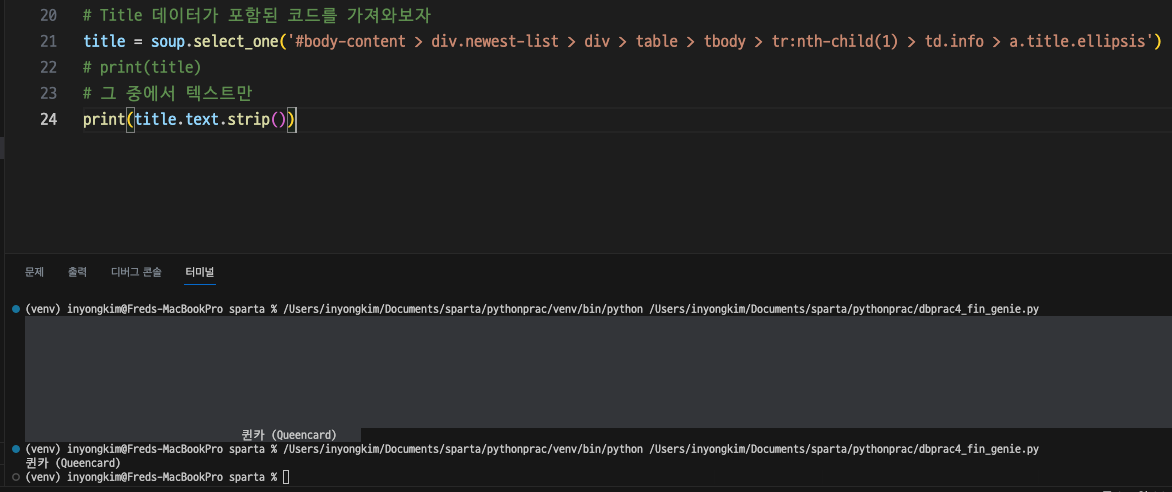
똑같은 방식으로 순위, 가수를 찾아보았다.
순위가 위치한 위치까지 계층
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number가수가 위치한 위치까지 계층
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
뭔가 이상한 부분이 있다.
rank, title, singer 순서대로 아웃풋을 살펴보면
rank가 ' 1
8상승'이라고 빈 공간, 하위 계층의 텍스트까지 출력되고있다.
내가 원하는 텍스트는 1이라는 순위 숫자이므로
파이썬 문자열 추출(슬라이싱) Slicing 콜론 [ : ] 사용으로
[0:2] = 0, 1, 2 3개 index까지만 자르고 나머지를 버리고 출력하도록 조건을 주었다.

이제 1개 데이터의 rank, title, singer를 원하는 상태로 추출 하고 있다.
2. 다수의 데이터 크롤링
tr들은 각 노래들이다.
tr > td에 rank, title, singer가 존재한다. (그중 (1)th-child 1개 데이터를 크롤링 한것이 윗부분)
그럼 tr"들"을 다뤄보자
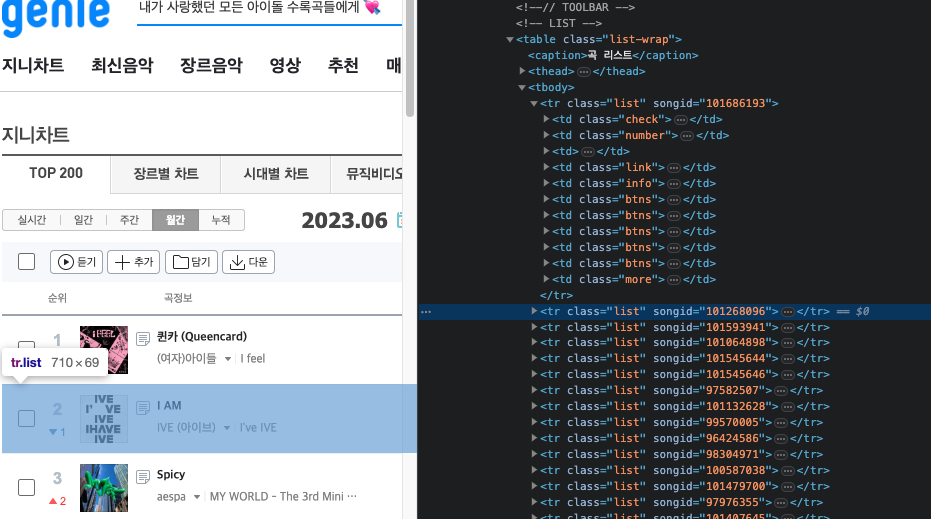
우선 tr이 위치한 계층 경로를 보자.
#body-content > div.newest-list > div > table > tbody > trtbody로 감싸진 부분에 tr태그가 수두룩빽빽이다. 각 tr마다 노래의 랭킹 순서대로 나타나있다.
이 tr들을 trs라는 변수에 select_one이 아닌 select로 리스트 객체에 담아둔다.
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')soup 객체에는 select_one() 함수와 select() 함수가 있습니다. 두 함수 모두 CSS 셀렉터로 원하는 엘리먼트를 찾아주는 기능을 한다는 점은 같지만
- select_one() 함수는: 처음으로 발견한 하나의 엘리먼트만 반환합니다
- select() 함수는 발견한 모든 엘리먼트를 리스트 형식으로 반환합니다.
이제 반복문을 통해 데이터 trs를 돌면서 tr에 rank,title,singer 변수에 td내용을 담고 변수들을 출력하는 것까지 를 trs 리스트가 모두 끝날때까지 실행해준다.
# 데이터는 td에 있고 상위 계층인 tr은 "곡"을 말한다. tr"들" 전체를 trs라고 변수에 담는다.
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
# 반복문으로 trs를 돌면서 [rank, title, singer 변수를 {tr}에 담고, 출력한 후 <다음 trs>로 넘어간다.] 를 반복(어디까지? trs 리스트의 끝까지==0부터 전체)
# 1싸이클 해석:
# tr 변수에 trs 첫번째 인덱스 = soup으로 받은 trs의 첫번째[0] <tr>데이터가 들어감
for tr in trs:
# 그 tr.select_one으로 순위 텍스트가 있는 곳인 td.number로 가서
# 텍스트를 0~2까지 자르고, 양옆 공백을 제거(strip)한 텍스트를
# rank변수에 담는다.
rank = tr.select_one('td.number').text[0:2].strip()
# title 동일, singer 동일
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
singer = tr.select_one('td.info > a.artist.ellipsis').text.strip()
# rank변수에 담긴것, + /구분선, title+ /, singer를 출력.
print(rank+" / ", title+" / ", singer)
# 하고 반복문 맨 위로 다시오면 trs에 담긴 다음 인덱스[1] <tr>데이터(두번째곡)가 들어감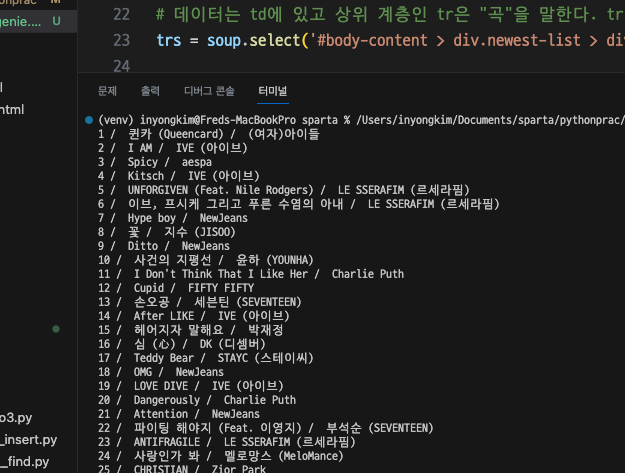
결과는 다음과 같이 원하는 양식대로 (순위 / 곡명 / 가수) 가 나타나게 되었다.
여기서 반복문에서
trs에 tr들이 담긴 것에서 혼동이 있었다.
아래 반복문 안에
"rank = tr.select_one(...)" 이 부분을
"rank = trs.select_one(...)" 과 같이 접근 했는데
# rank변수에 담는다.
rank = trs.select_one('td.number').text[0:2].strip()처음 생각엔
trs. 이라는것이..
단순히 trs라 지정한것이 "... > tr" 까지기 때문에
이어서 "... > tr" + "> td.number"로 접근하면
원하는 총 경로에 있는 데이터를 rank에 넣는다 착각했다.
이해가 되지 않아서 검색했더니 생각해보니 for ... in 반복문에 대한 이해도가 부족했다.
trs리스트의 반복문이 시작될 때
이미 첫번째 trs데이터(리스트의 첫번째 데이터)가 tr이란 변수에 들어가서 돌고 있기 때문에
tr을 써줬어야 한다. 이 변수는 지정하기 나름이다.
이건 내가 무언가 객체 내부를 접근하는 " . " (점표기법)과 혼동이 있는 것 같다.
반복문에 대해서 좀 더 익숙해질 필요성을 느꼈다.
해당 스터디는 아래 깃을 통해 업데이트 되고 있습니다.
https://github.com/yzpocket/Sparta99training
GitHub - yzpocket/Sparta99training
Contribute to yzpocket/Sparta99training development by creating an account on GitHub.
github.com
'Python&Flask Tutorials, AWS EB > 3rd WEEK Python, Crawling, MongoDB' 카테고리의 다른 글
| [3주차 회고] Python, Crawling, MongoDB, Atlas Cloud DB 배운점, 어려웠던점 (0) | 2023.07.08 |
|---|---|
| [Python][Database] DB에 저장된 데이터를 수정하기(Update) update_one (0) | 2023.07.06 |
| [Python][Database] DB에 저장된 데이터를 찾기(Read) find_one, find (0) | 2023.07.06 |
| [Python][Database] 웹 크롤링 데이터를 DB에 넣기(Create) Insert_one (0) | 2023.07.06 |
| [Python][Database] MongoDB CRUD SQL 연습 (0) | 2023.07.05 |


