
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- requests
- atlas
- body
- openapi
- frontend
- CSS
- mongodb
- POST
- javascript
- flask
- Project
- synology
- get
- OOP
- Algorithm
- venv
- backend
- mysql
- PYTHON
- NAS
- github
- pymongo
- Crawling
- portfolio
- beautifulsoup
- java
- fetch
- flaskframework
- CRUD
- json
- Today
- Total
wisePocket
[Python][Database] DB에 저장된 데이터를 찾기(Read) find_one, find 본문
[Python][Database] DB에 저장된 데이터를 찾기(Read) find_one, find
ohnyong 2023. 7. 6. 22:01requests, beautifulsoup 라이브러리를 활용하여 웹 페이지의 원하는 정보를 크롤링하고 DB에 insert하는 과정까지 진행했다.
이번에는,
웹 크롤링 한 데이터를 Insert한 DB 자료를
- DB에서 원하는 정보를 찾아오는 == Read == Find_one / Find
를 진행해보려 한다.
0. Insert 복습
우선 insert 과정을 복습할겸 db.movies2 라는 collection에
2010년 영화 랭킹 웹 페이지에서 새로 데이터를 insert했다.
movies2 collection에 데이터를 넣는 스크립트는 다음과 같다.
# 웹 크롤링을 위한 requests, bs4 Import
import requests
from bs4 import BeautifulSoup
# Python과 DB를 연결하는 코드(공통)
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://ohnyong:test@cluster0.lu7mz8j.mongodb.net/?retryWrites=true&w=majority',tlsCAFile=ca)
db = client.dbsparta
# 웹 크롤링 구현
URL = "https://movie.daum.net/ranking/boxoffice/yearly?date=2010"
# user agent는 HTTP 요청을 보내는 디바이스와 브라우저 등 사용자 소프트웨어의 식별 정보를 담고 있는 request header의 한 종류이다.
# 임의로 수정될 수 없는 값이고, 보통 HTTP 요청 에러가 발생했을 때 요청을 보낸 사용자 환경을 알아보기 위해 사용한다.
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# URL로부터 requests.get으로 HTML 소스를 data에 담는다
data = requests.get(URL, headers=headers)
# BeautifulSoup으로 data(html 소스)를 soup에 담는다(bs의 기능을 기능을 이용하기 위해)
soup = BeautifulSoup(data.text, 'html.parser')
# soup에 담긴 data중에 list_movieranking > li 에 속한 요소들을 lis에 담는다
lis = soup.select(".list_movieranking > li")
# for in 반복문은 객체에 주로 사용합니다.
# 즉, 객체 자료형에 자료들을 하나씩 꺼내고 싶을때 사용
# //key를 받는 변수명은 임의변경 가능
# //in 객체명
# for (key in book) {
# console.log(key, book[key]);
# }
# 객체에 사용 할수 있습니다.
# 객체의 key값과 value 값을 뽑아내는데 유용합니다.
# 객체의 키값의 갯수만큼 반복하여 첫번쨰키값부터 마지막 키값까지 반복합니다.
# 1] lis 객체에서 li라고 명칭한 변수에 다음을 반복 실행한다 객체의 마지막 키값까지.
for li in lis:
# 2] rank, age, title 변수에 li중 .rank_num, .ico_see, .link_txt 값을 담는다
rank = li.select_one(".rank_num").text
age = li.select_one(".ico_see").text
title = li.select_one(".link_txt").text
print(rank, title, age)
# 3] 위 변수를 doc에 rank, title, age key값의 각각 value로 넣는다.
doc = {
'rank': rank,
'title': title,
'age': age
}
# 4] movies2라는 collection에 doc에 담긴 데이터를 document로 insert 한다.
db.movies2.insert_one(doc)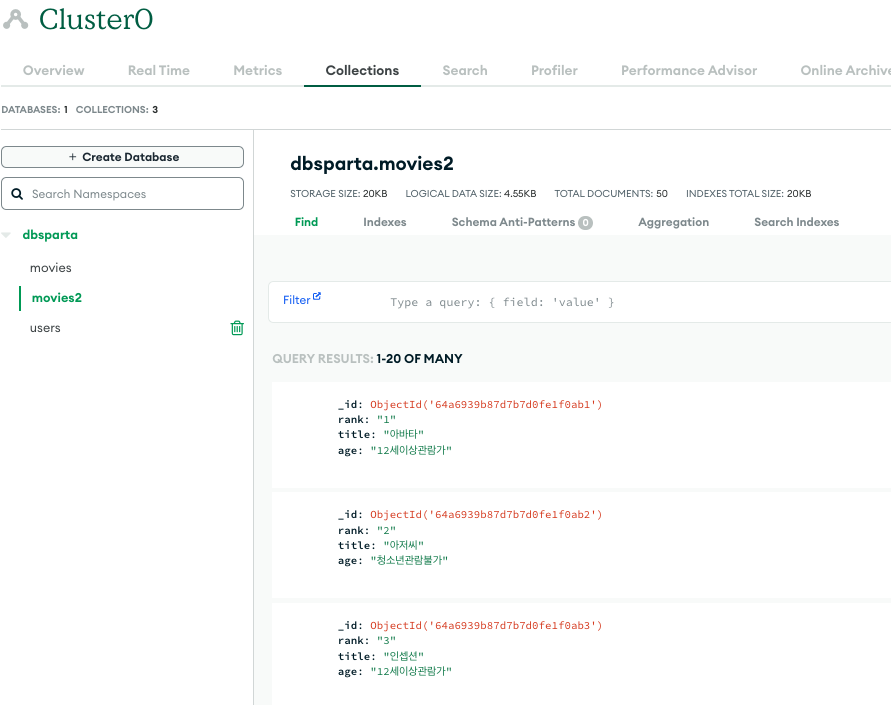
1.1 Read == Find_one
DB에 저장된 데이터중에
"영화 제목 '아저씨'의 순위를 가져오자"
- 영화 제목 = title이라는 key
- 아저씨 = title의 value값
- 순위 = rank라는 key의 value
1개 찾기 find_one 코드는 다음과 같다.
#[1] 가져온다 == Find를 사용하자
# "영화 제목 '아저씨'의 순위를 가져오자"
# READ(FIND_ONE)
# 한 개 찾기 - 예시
movie = db.movies2.find_one({'title':'아저씨'})
print(movie)
#그 중에서 순위(rank) 가져오기.
print(movie['rank'])
1.2 Read == Find_one + Find
DB에 저장된 데이터중에
"영화 제목 '하모니'와 같은 연령제한 영화들의 제목들을 가져오자"
- 영화 제목 '하모니'= title의 value가 '하모니'인 데이터
- 같은 연령제한 = 위 데이터의 'age' key값의 value와 동일한
- 영화들의 제목 = 위 조건을 가진 title들을 반복문으로 추출
영화 제목 '하모니'와 같은 연령제한
마찬가지로 1개 찾기 find_one 코드를 먼저 사용하게 된다.
find_one으로 '하모니' 영화 데이터 정보를 가져온다.
그 중 'age'라는 key값이 '연령 제한'을 표현하고 있다.
해당 영화의 '연령 제한' value값을 age라는 변수에 일단 담아둔다.(이것은 원하는 데이터로 정렬하는 조건의 기준점이 될 것이다.
# READ(FIND)
# 우선 조건 기준을 삼으려는 _1개의 데이터_를 찾는다.
movie = db.movies2.find_one({'title':'하모니'})
print(movie)
# '하모니' 영화의 연령제한이 기준점이 되고 'age'라는 변수에 담는다.
age = movie['age']
print(age)
age라는 기준점을 변수에 담았으니
기준점까지 포함된 여러개 찾기 find 코드는 다음과 같다.
# READ(FIND)
# 우선 조건 기준을 삼으려는 _1개의 데이터_를 찾는다.
movie = db.movies2.find_one({'title':'하모니'})
print(movie)
# '하모니' 영화의 연령제한이 기준점이 되고 'age'라는 변수에 담는다.
age = movie['age']
print(age)
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
# 'age'가 위 movie'하모니'의 age값인 조건 추가하여
# list()로 movies라는 객체 생성
movies = list(db.movies2.find({'age':age},{'_id':False}))
# 객체기 때문에
for m in movies:
print(m)'age'가 : age변수(기준)인 데이터들을 movies2 collection에서 찾아서 movies라는 객체에 넣는다.
이후 for in 반복문을 통해 movies 객체의 내용을 print 한다.
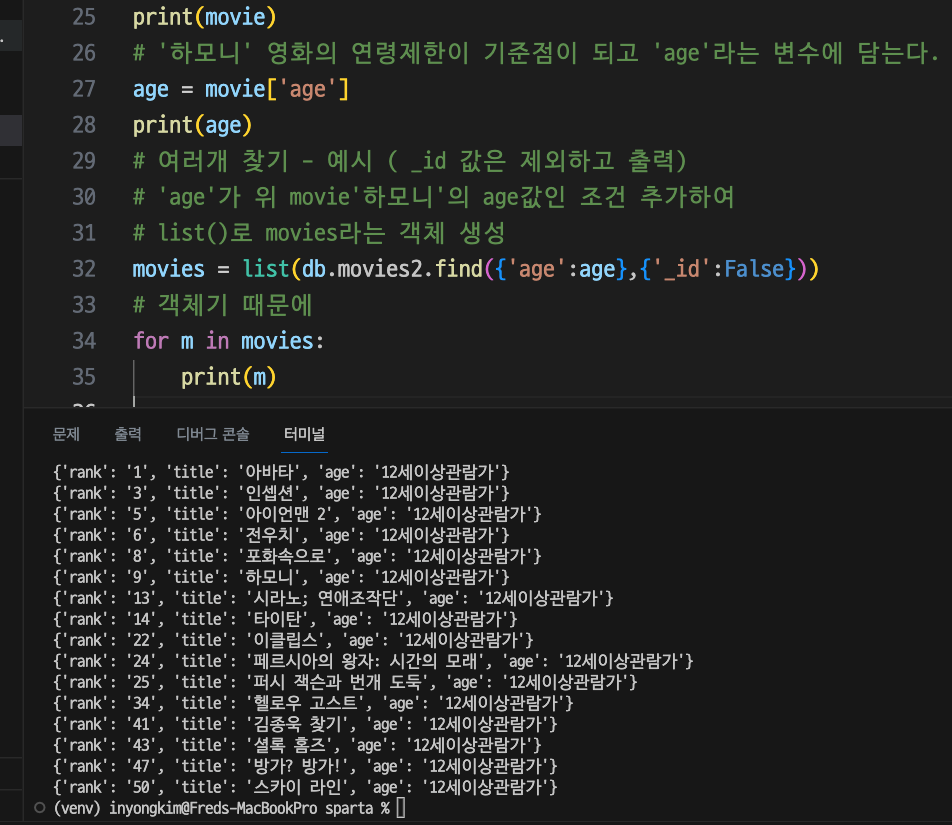
'12세이상관람가'인 movie2 컬렉션의 모든 영화들의 정보를 가져(read, find)와서 print 되고 있다.
해당 스터디는 아래 깃을 통해 업데이트 되고 있습니다.
https://github.com/yzpocket/Sparta99training
GitHub - yzpocket/Sparta99training
Contribute to yzpocket/Sparta99training development by creating an account on GitHub.
github.com
'Python&Flask Tutorials, AWS EB > 3rd WEEK Python, Crawling, MongoDB' 카테고리의 다른 글
| [Python] "Genie" 지니 음악 차트 데이터 크롤링 실습 (0) | 2023.07.07 |
|---|---|
| [Python][Database] DB에 저장된 데이터를 수정하기(Update) update_one (0) | 2023.07.06 |
| [Python][Database] 웹 크롤링 데이터를 DB에 넣기(Create) Insert_one (0) | 2023.07.06 |
| [Python][Database] MongoDB CRUD SQL 연습 (0) | 2023.07.05 |
| [Python][Database] MongoDB Atlas(Cloud)와 Python 연결 dnspython , pymongo 라이브러리 + SSL: CERTIFICATE_VERIFY_FAILED 에러 해결 (0) | 2023.07.05 |



