
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- frontend
- backend
- portfolio
- atlas
- openapi
- PYTHON
- get
- synology
- github
- pymongo
- POST
- requests
- CSS
- beautifulsoup
- NAS
- mongodb
- json
- body
- OOP
- javascript
- flaskframework
- CRUD
- mysql
- fetch
- Crawling
- flask
- java
- venv
- Algorithm
- Project
- Today
- Total
wisePocket
[Flask] Flask framework 미니프로젝트(project fan) 03 (웹 크롤링 기능 부분 구현 및 테스트, 시행착오와 해결 soup.find(string), .parent 의문) 본문
[Flask] Flask framework 미니프로젝트(project fan) 03 (웹 크롤링 기능 부분 구현 및 테스트, 시행착오와 해결 soup.find(string), .parent 의문)
ohnyong 2023. 7. 17. 14:33개발하고자하는 프로젝트는 웹 크롤링을 이용한다는 점이다.
해당 부분의 기능을 테스트용으로 먼저 구현하고,
본 프로젝트에 삽입 할 예정이다.
실습 내용엔 없지만 스스로 복습겸 구현해보고 싶어서 추가한 기능이다.
| #### 웹 크롤링 - URL로부터 Super Shy의 데일리 랭킹 크롤링(soup.select_one) |
1. 테스트용 URL
URL : https://kworb.net/spotify/country/us_daily.html
Spotify Daily Chart - United States
146 -5 44 5 347,383 -20,188 2,554,957 -32,059 27,023,386
kworb.net
공식 차트에서는 크롤링이 되지 않아서 타 웹 페이지에서 Spotify의 차트를 제공하고 있어 해당 URL을 대상으로 테스트를 진행하려한다.
2. URL로 들어가서 Super Shy 랭킹 소스 확인하기
Spotify 공식 홈페이지의 차트에서는 크롤링이 불가능하다
Spotify의 일일 랭킹이 기록되는 kworb.net에서 크롤링을 진행하기로 결정했다.
URL로 들어가서 해당 웹 페이지의 소스를 확인해보면
<tbody>태그 내에 tr>td로 각 노래의 랭킹을 확인 할 수 있다.

3. 웹 크롤링을 위한 requests, Beautifulsoup 임포트 및 URL의 HTML 파싱
- 웹 크롤링 테스트를 위한 crawl_test.py를 생성
- 웹 크롤링을 위한 requests 임포트
- 크롤링한 HTML을 text로 변환 parsing할 BeautifulSoup 임포트
- requests.get()을 통해 URL의 데이터(HTML 소스)를 받고 data라는 변수에 담기
- beautifulsoup()으로 data를 text 형태로 파싱, 구문 분석하여 soup이란 변수에 담기
# 크롤링 = 웹페이지에서 어떤 데이터를 가져오는것
import requests
from bs4 import BeautifulSoup
URL = "https://kworb.net/spotify/country/us_daily.html"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')4. 원하는 데이터를 가져와보자
- 해당 웹 페이지의 HTML을 살펴보면
- html>body>div.container>div.subcontainer:nth-child(2)>table#spotifydaily 태그 안에 tbody에 원하는 데이터(곡 정보들)가 <tr>들로 담겨져 있다.

- 선택하기 쉽도록 테이블이 id가 지정되있으므로 간략하게 #spotifydaily > tbody > tr 로 정리 할 수 있다.
- 우선 차트까지를 trs라는 변수에 담아둔다.
# BeautifulSoup 라이브러리는 엄청 많은 HTML 코드 중에 우리가 원하는 특정 부분 을 빠르고 쉽게 필터링 해주는 라이브러리이다.
# 원하는 데이터만 추출해보자
# 상위 계층인 tbody은 "차트"이다.
# 실제 데이터(한곡, 한곡들)들 은 tr에 있다. 우선 tr"들" 전체를 trs라고 변수에 담는다.
trs = soup.select('#spotifydaily > tbody > tr')
print(trs)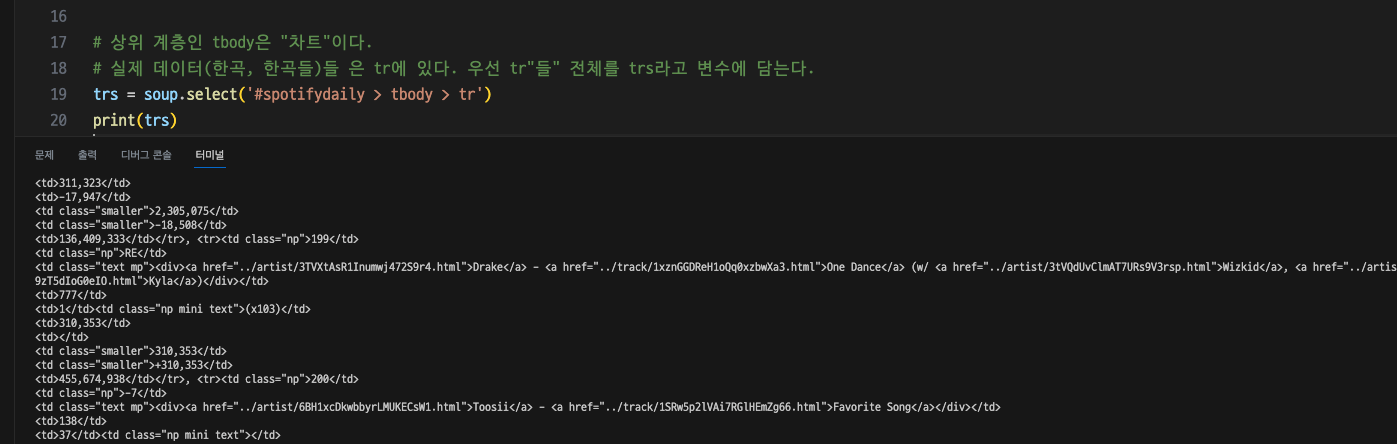
- soup의 select_one()을 통해 soup에 담긴 HTML 소스 중 원하는 값이 있는 태그를 지목하고 해당 값을 선택할 수 있다.
- trs에 모든 곡들이 들어 있으므로 반복문으로 모든 랭킹을 찾아본다.
# 반복문으로 trs를 돌면서 [rank, rankdiffer, artist, title 변수를 담는다] 를 반복(어디까지? trs 리스트의 끝까지==0부터 전체)
for td in trs:
# 양옆 공백을 제거(strip)한 텍스트를 추출하고자 한다. 데이터가 깔끔해서 slice기능을 사용할 필요는 없었다.
# title tr>td중에 text mp라는 클래스td 안에 데이터가 있는데 내부에 tr>td>div>a태그까지 넘어가야 실질적인 데이터가 있다.
# rank변수에 담는다. tr>td의 첫번째 요소이므로 first-child를 사용했다.
rank = td.select_one('td:first-child').text.strip()
rankdiffer = td.select_one('td:nth-child(2)').text.strip()
# 또한 a태그는 2~3개인 경우가 있다. nth-child로 정리하려했으나 가끔 두번째 a태그에 제목이 겹치는 데이터가 있었다.
# 따라서, 첫번째가 가수, 마지막(2개인 경우엔 2번째, 3개인 경우 3번째)에 노래 제목인 규칙을 보고
# first-child에 가수, last-child에 노래 제목인 것으로 정리했다.
artist = td.select_one('td.text.mp > div > a:first-child').text.strip()
title = td.select_one('td.text.mp > div > a:last-child').text.strip()
# 변수에 담긴것이 정확한지 콘솔로 확인해본다.
print("Rank : "+rank+"\t", "DIFF : "+rankdiffer+"\n","Artist : "+artist+"\n", "Title : "+title)
여기까지 왔을때 무언가 잘못된 것을 느꼈다.
내가 원하는 정보는 Super Shy의 순위, 랭킹 변화 이다.
지금 추출한 데이터는 모든 랭킹 순위이고, 데이터를 특정 하지 못했다.
이전 연습 샘플 모듈을 사용 할 때 주의해야 할 점이다.
비슷한 기능과 원하는 기능은 다른것인데 모든 랭킹 차트를 크롤링하는 것으로 착각하고 몰입되었다.
또다른 문제, 내가 원하는 데이터는 특정 태그 안에 고정되어 위치하지 않아서 선택자로 지정하기 애매하다. (매일 랭킹 순위가 변경되므로 <tr>태그의 순서(자식순서)가 변경된다. nth로 특정 순위를 지정해버리면 다음날 순위가 변경되면 다른 곡의 정보가 나타날 수 있다.
따라서 soup에서 특정 텍스트를 검색하는 기능이 있는지 살펴보았다.
하지만
soup.find는 css 속성, 클래스, id 등이 지정된 경우에 찾을 수 있다.
soup.select 또한 위와 마찬가지로 기능이 태그에 의존되어 있다.
따라서 DB를 통해 전체 랭킹을 저장하고 원하는 텍스트(Super Shy)가 있는 document를 찾가서 그 랭킹 숫자를 가져오는 방법으로 가는 것이 맞을 것 같다.
여기서 비지니스 로직을 결정해야 한다.
1. 클라이언트에서 접속 할 때마다->해당 URL의 페이지를 크롤링->DB업데이트->DB에서 해당 값(Super Shy)를 찾아서 가져와서-> 클라이언트에 보여주기
2. 클라이언트 접속 할 때 -> URL페이지 크롤링 -> 어떻게든 Super Shy 텍스트에 접근해서 -> 부모태그들로 접근하여 값 가져와서 -> 클라이언트에 보여주기
super shy라는 텍스트를 찾아내고 상위(부모)태그로 접근하는 방법도 고민했다.
soup의 .parent 태그로 가는것을 찾아보았지만 역시 일단 find또는 select로 선택자를 특정해야한다. 분명히 쉽게 접근 할 수 있을텐데,
라고 좌절 할 뻔했지만 못참고 더 구글링 하다가 내가 원하던 해결방법을 찾아냈다. 또한 모든 랭킹을 DB에 넣고, 업데이트하고 하는 비지니스 로직은 생각보다 너무 무식? 한 방법이라 생각되었다. 궂이 방법이 있을텐데 모든 데이터를 저장할 필요가 있을까? 또한 계속 데이터를 저장, 업데이트 하고 찾으면 성능적으로 당연히 느릴 수 밖에 없다. 또한 기능 구현 자체도 DB까지 건들여야 하나? 200개중에 1개의 데이터를 위해서? 아는 방법으로 우회하기보다는 스스로 모르는 부분을 찾아보기 시작했다.
다시 내가 원하는 기능을 명확히 정의했다.
string or text(특정 텍스트)를 soup에 담겨있는 HTML 소스중에서 찾는 것이 목적이다.
soup string 이란 키워드로 구글링을 시작했다.
내가 원하는 것을 해결한 것은 다음과 같이 정리해본다.
| 1. soup에 담긴 html 소스 중에서 Super Shy 라는 텍스트를 찾아내야 한다. 이것을 해결하는데 근본적으로 soup의 select()와 find()클래스를 살펴보았다. VSCode에서 제공하는 툴팁에서도 나타나는데 바보같이 자세히 살펴보지 못했다. 내가 원하는 것은 string 파라미터를 받을 수 있는지 여부다. soup.select() 메서드의 내용이다. select에서는 selector, namespace, flags.. 등등 파라미터를 받을 수 있다. 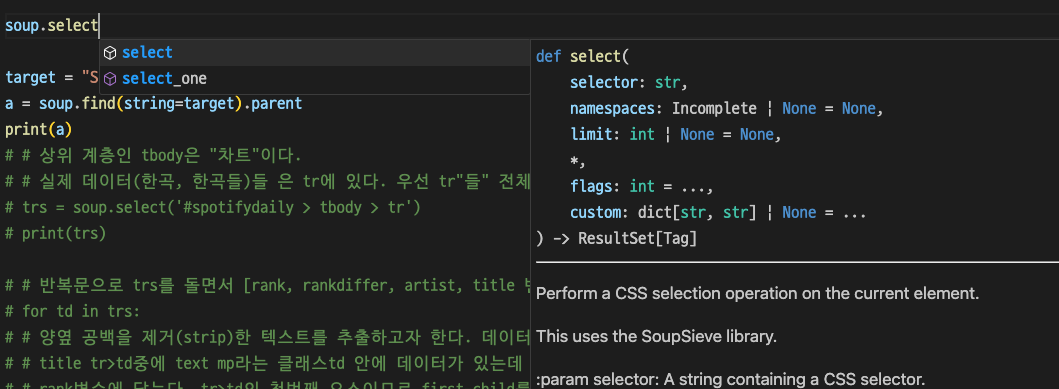 soup.find() 메서드의 내용이다. 파라미터 중에서 string을 받을 수 있다. 말그대로 string을 받아서 찾아준다! 라고 볼 수 있다. 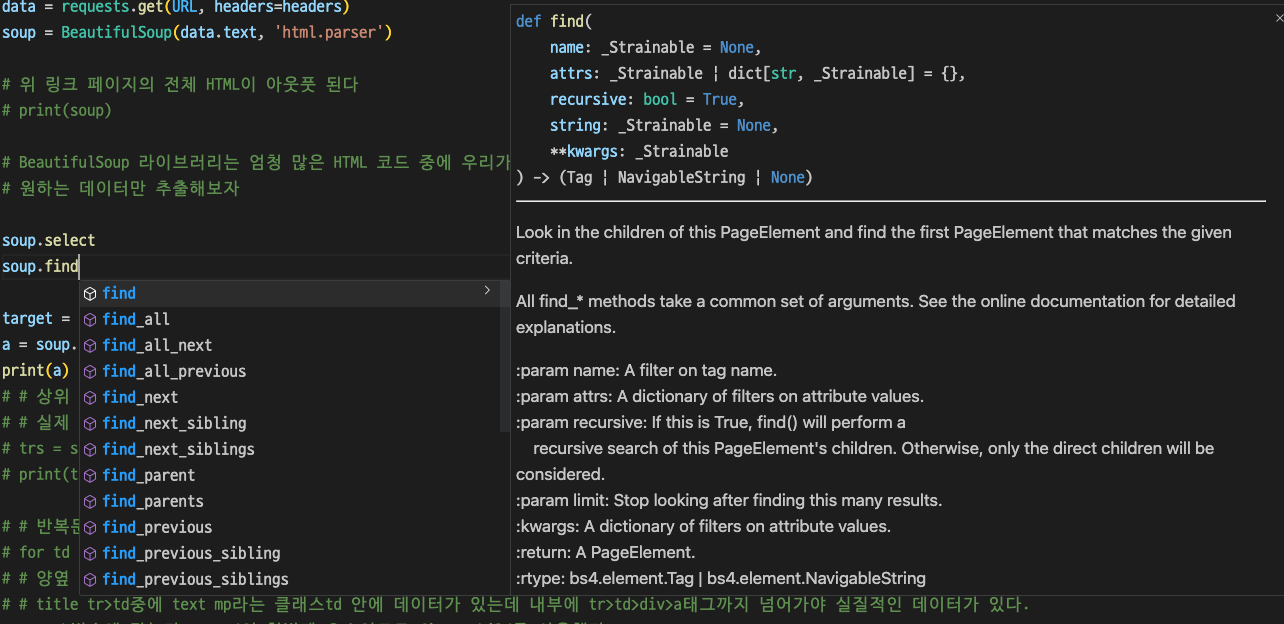 https://www.crummy.com/software/BeautifulSoup/bs4/doc/#find-parents-and-find-parent  2.텍스트를 찾아냈으면 부모태그로 접근해서 랭킹 등 데이터를 가져온다. https://www.crummy.com/software/BeautifulSoup/bs4/doc/#parent   |
다시 처음부터
soup(HTML이 담겨 있음)에서 Super Shy를 찾는지 살펴보자.
# BeautifulSoup 라이브러리는 엄청 많은 HTML 코드 중에 우리가 원하는 특정 부분 을 빠르고 쉽게 필터링 해주는 라이브러리이다.
# 원하는 데이터만 추출해보자
target = "Super Shy"
a = soup.find(string=target)
print(a)콘솔에서 Super Shy라는 타겟을 찾아내고 있다.
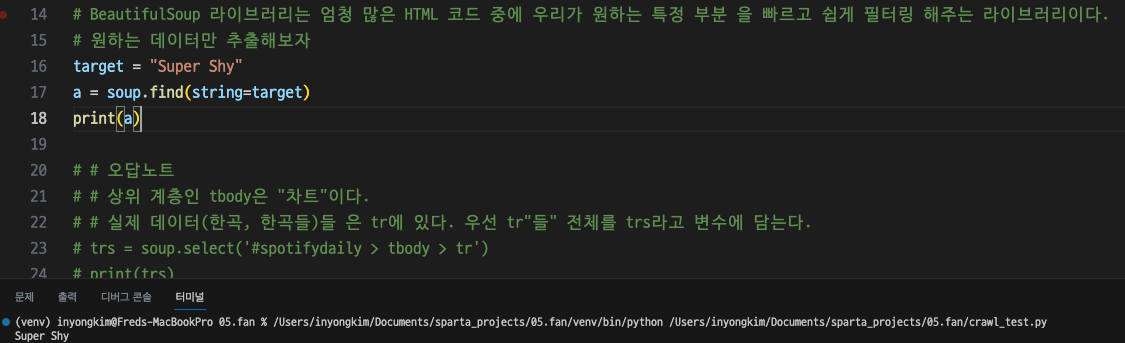
이제 Super Shy라는 HTML소스 중 가장 하위 계층의 텍스트를 찾았다.
한 단계씩 위 부모태그로 find 범위를 넓혀보자.
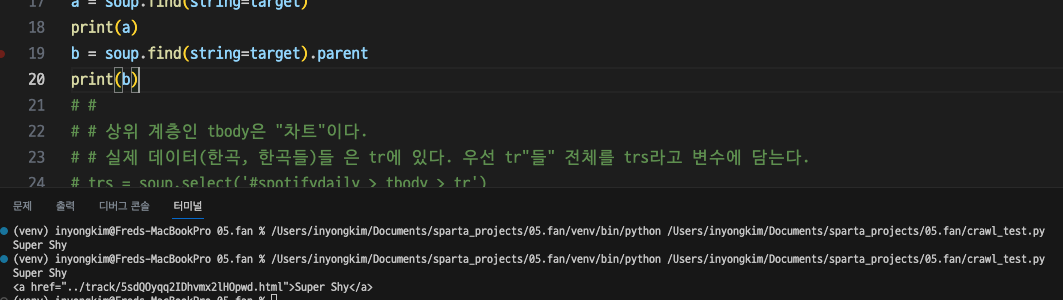


4번 부모 계층을 넘어선 다음부터 내가 원하는 데이터인 Super Shy라는 곡 명과 순위, 순위변동, 가수명까지 나타났다.
내가 원하는 정보가 담긴(Super Shy라는 텍스트로 역추적한) HTML소스는 e라는 변수에 담아두었다.

5. 필요한 것들을 정리하자
e라는 변수에 특정 텍스트로부터 부모 태그를 거슬러 올라가서 원하는 정보들만 담긴 HTML 소스를 담았다.
e에서 select_one으로 원하는 값들만 추출하자.

- 순위 : 현재 Super Shy 노래의 일일 순위이다. rank변수에 담는다. tr>td의 첫번째 요소이다.
- 순위변동 : 전일과 비교하여 변동된 순위이다. rankdiffer변수에 담는다. tr>td의 두번째 요소이다.
- 가수 : Super Shy 노래의 가수 이름이다. artist변수에 담는다. text mp라는 클래스 td>div>a 태그의 첫번째 요소이다.
- 노래명 : Super Shy 노래 이름이다. title 변수에 담는다. text mp라는 클래스 td>div>a 태그의 마지막 요소이다. (* nth-child(2)로 안한 이유는 해당 차트에서는 가끔 featuring 가수가 두번째 요소로 들어갈 때가 있다. 범용성을 위해서 마지막 요소로 지정)
# 순위 rank변수에 담는다. tr>td의 첫번째 요소이다.
# 순위변동 rankdiffer변수에 담는다. tr>td의 두번째 요소이다.
rank = e.select_one('tr > td:first-child').text.strip()
rankdiffer = e.select_one('tr > td:nth-child(2)').text.strip()
# a태그는 2~3개인 경우가 있다. nth-child로 정리하려했으나 가끔 두번째 a태그에 제목이 겹치는 데이터가 있었다.
# 따라서, 첫번째가 가수, 마지막(2개인 경우엔 2번째, 3개인 경우 3번째)에 노래 제목인 규칙을 보고
# first-child에 가수, last-child에 노래 제목인 것으로 정리했다.
artist = e.select_one('td.text.mp > div > a:first-child').text.strip()
title = e.select_one('td.text.mp > div > a:last-child').text.strip()
# 변수에 담긴것이 정확한지 콘솔로 확인해본다.
print("Rank : "+rank+"\t", "DIFF : "+rankdiffer+"\n","Artist : "+artist+"\n", "Title : "+title)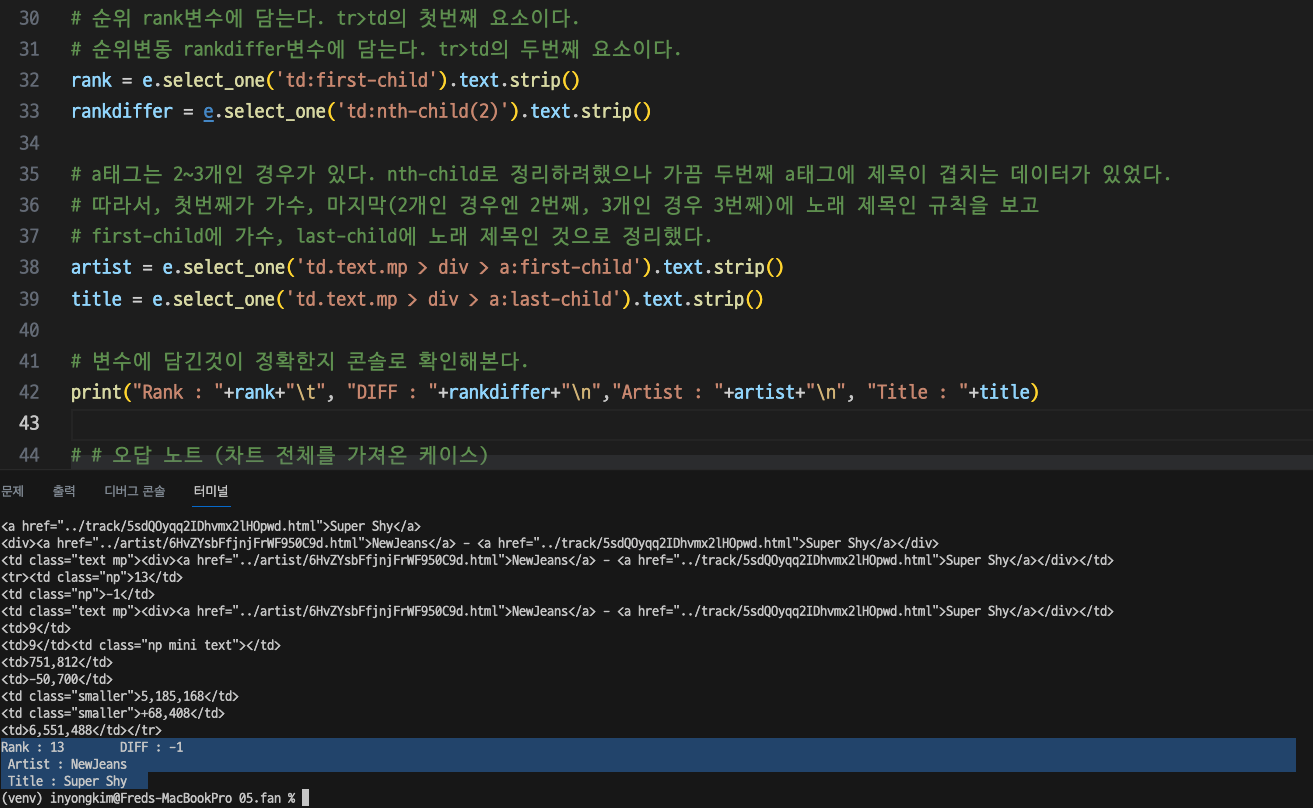
이제 URL로부터 Super Shy의 순위, 순위변동, 노래명, 가수를 얻어오는 것을 완성했다.
아직도 텍스트로부터 역으로 부모 태그를 찾아가서 e로 저장한
이 부분이 지저분해서 마음에 안든다. 다른분들은 같은 기능을 어떻게 구현할까?
target = "Super Shy"
e = soup.find(string=target).parent.parent.parent.parent
해당 프로젝트는 아래 깃을 통해 업데이트 되고 있습니다.
https://github.com/yzpocket/Flask_project_fan
GitHub - yzpocket/Flask_project_fan
Contribute to yzpocket/Flask_project_fan development by creating an account on GitHub.
github.com



