
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Algorithm
- portfolio
- CRUD
- synology
- Crawling
- flaskframework
- atlas
- Project
- POST
- beautifulsoup
- backend
- CSS
- NAS
- pymongo
- get
- mysql
- OOP
- json
- requests
- flask
- frontend
- openapi
- java
- github
- javascript
- venv
- body
- PYTHON
- fetch
- mongodb
- Today
- Total
wisePocket
[Flask] Flask framework 미니프로젝트(project fan) 09 (Backend Super Shy 랭킹 웹 크롤링 및 보기 기능 구현) 본문
[Flask] Flask framework 미니프로젝트(project fan) 09 (Backend Super Shy 랭킹 웹 크롤링 및 보기 기능 구현)
ohnyong 2023. 7. 18. 14:59이전 03 웹 크롤링 기능 부분 구현 및 테스트, 시행착오와 해결에서 기능 테스트 부분을 구현했다.
https://ohnyong.tistory.com/95
해당 기능 모듈을 본 프로젝트에 활용하고자 한다.
전반적으로 GET방식 요청, 응답과 같은 흐름이다.
전체적인 클라이언트와 서버 간의 흐름을 요약하면 다음과 같다.
- 우선 프론트에서 웹 페이지 로드가 되면 (document).ready()에 따라
- 백엔드 요청은 JavaScript의 /ranking이라는 URL로 해당 데이터를 요청하게 설계했다.
- 이후 응답은 app.py에서는 /ranking 요청에 대한 응답을 준비하는데
- 웹 크롤링을 시작(테스트 코드로 사전 진행함)
- 지정한 URL에서 진행
- requests로 HTML소스 받음
- beautifulsoup으로 정리하기 쉽도록 분석, 정렬
- soup의 find, select를 통해 원하는 데이터 추출
- 데이터를 추출한 이후->정리(리스트화)해주고->json형태로 다시 JavaScript로 반환시켜줌-> Promise 데이터로 변환 -> 자리표시자${variable}로 쉽게 원하는 곳에 입력
따라서 이미 08 GET방식으로 View 페이지에 응원 댓글 목록 보기 기능 구현을 했기 때문에 비슷한 흐름 중에 응답 부분에 웹 크롤링 데이터로 가수이름, 노래제목, 오늘 순위, 순위 변동을 받아서 View 페이지에 넣어주는 기능을 작성해야 한다.
| #### 웹 크롤링 - URL로부터 Super Shy의 데일리 랭킹 크롤링(soup .find, .select_one) |
1. 데이터 명세
- URL : https://kworb.net/spotify/country/us_daily.html
- Contents :
- 가수 이름 : 'artist': artist / from URL #spotifydaily>tbody>tr>td.text mp
- 노래 제목 : 'title': title / from URL #spotifydaily>tbody>tr>td.text mp
- 오늘 순위 : 'rank' : rank / from URL #spotifydaily>tbody>tr>td.np
- 순위 변동 : 'rankdiffer' : rankdiffer / from URL#spotifydaily>tbody>tr>td.np
2. 서버 만들기
서버 실행을 위한 라이브러리 임포트와 서버 실행 포트 설정은 GET, POST 기초 테스트에서 이미 작성되었다.
웹 크롤링을 위한 requests, beautifulsoup을 임포트 한다.
# [Ranking GET-2] 웹 크롤링을 위한 임포트
# 크롤링 = 웹페이지에서 어떤 데이터를 가져오는것
import requests
from bs4 import BeautifulSoup3. 기능 구현을 위한 app.py 부분 수정 및 작성
이전 테스트로 서버 시작 및 브라우저로 URL 입력하여 메인 View 페이지 요청에서 GET 요청, 응답 연결되는 것을 확인했기 때문에
우선 app.py부분부터 테스트 코드를 수정하여 원하는 기능을 구현하고자 한다.
개발 순서는 app.py 이후 html을 보며 js를 작성하는 것이 편하지만 요청, 응답, 데이터 흐름 순서는 별도로 표기해 두었다.
메인 View 페이지 요청에서 show_ranking()의 fetch() 실행 이후
- [기능 흐름 순서 2]
- app.py에서 '/ranking' URL의 GET 방식 요청에 대한 메서드로 접근
- 이는 ranking_get()라 선언된 함수를 실행하는데
- 웹 크롤링을 위해 requests, beautifulsoup을 임포트
- 크롤링할 url을 지정하고 requests.get()으로 url의 HTML소스가 data로-> beautifulsoup()에 의해 파싱(분석)되어 soup에 담긴다.
- soup의 find()로 텍스트인 "Super Shy"의 위치를 찾아내고 부모 태그로 이동하면서 원하는 데이터인 가수, 노래 제목, 오늘 순위, 순위 변동까지 나타난 계층의 2차적으로 정리된 HTML소스를 획득
- soup의 select_one()으로 정리된 소스 내 가수 이름, 노래 제목, 오늘 순위, 순위 변동을 각각 지명하여 각 artist, title, rank, rankdiffer변수에 담는다.
- 다음 Dictionary 형식의 리스트 데이터를 갖는 rankingdoc이라는 객체 생성
- 위 변수들에 request.form을 통해 저장한 데이터는 아래 각 value로 들어가고 doc객체 내에 담긴다.
- 'artist' : artist,
'title' : title,
'rank' : rank,
'rankdiffer' : rankdiffer
- 'artist' : artist,
- 위 4개 key:value 묶음을 가진 객체는 이후, 확인용으로 {'rankingresult' : rankingdoc} 라 에 key, value(list) 형태로가
- jsonify()에 의해 json 형식의 데이터로 변환(주어진 값과 대응하는 JSON 문자열) 후 반환하고 js로 이동
# [Ranking GET-2] 웹 크롤링을 위한 임포트
# 크롤링 = 웹페이지에서 어떤 데이터를 가져오는것
import requests
from bs4 import BeautifulSoup
# [Ranking GET-3] 웹 크롤링 URL 지정과 requests를통한 데이터 가져오기->bs를 통한 파싱
URL = "https://kworb.net/spotify/country/us_daily.html"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
...
# [Ranking GET-0] /ranking URL에서 GET 방식으로 요청에 대한 반환 데이터를 작성
# fetch('URL')부분, 반환값은 res로 전달.
# "localhost:5001/ranking" URL GET방식 요청에 응답
@app.route("/ranking", methods=["GET"])
def ranking_get():
# [Ranking GET-1] 웹 크롤링을 위한 임포트부터 시작한다. 맨위로
# 위 링크 페이지의 전체 HTML이 아웃풋 된다
# print(soup)
# [Ranking GET-4] 특정 텍스트로 원하는 범위 만큼의 HTML소스 가져오기(CLASS, ID가 지정안되서 해당 방법 사용)
# BeautifulSoup 라이브러리는 엄청 많은 HTML 코드 중에 우리가 원하는 특정 부분 을 빠르고 쉽게 필터링 해주는 라이브러리이다.
# 원하는 데이터만 추출해보자
target = "Super Shy"
# 테스트 코드에서 정리된 원하는 데이터 위치
e = soup.find(string=target).parent.parent.parent.parent
print(e)
# title tr>td중에 text mp라는 클래스td 안에 데이터가 있는데 내부에 데이터들이 있는 자식 태그 경로가 상이하다.
# [Ranking GET-5] 원하는 범위의 HTML소스에서 원하는 요소 선택 및 변수에 담기
# 순위 rank변수에 담는다. tr>td의 첫번째 요소이다.
# 순위변동 rankdiffer변수에 담는다. tr>td의 두번째 요소이다.
rank = e.select_one('tr > td:first-child').text.strip()
rankdiffer = e.select_one('tr > td:nth-child(2)').text.strip()
# a태그는 2~3개인 경우가 있다. nth-child로 정리하려했으나 가끔 두번째 a태그에 제목이 겹치는 데이터가 있었다.
# 따라서, 첫번째가 가수, 마지막(2개인 경우엔 2번째, 3개인 경우 3번째)에 노래 제목인 규칙을 보고
# first-child에 가수, last-child에 노래 제목인 것으로 정리했다.
artist = e.select_one('td.text.mp > div > a:first-child').text.strip()
title = e.select_one('td.text.mp > div > a:last-child').text.strip()
# 변수에 담긴것이 정확한지 콘솔로 확인해본다.
print("Rank : "+rank+"\t", "DIFF : "+rankdiffer+"\n","Artist : "+artist+"\n", "Title : "+title)
# [Ranking GET-6] 원하는 값을 반환 시켜 주기
# 이 값들을 rankresult에 담아서 프론트로 반환시켜 보내주자.
rankingdoc = {
'artist' : artist,
'title' : title,
'rank' : rank,
'rankdiffer' : rankdiffer
}
return jsonify({'rankingresult': rankingdoc})4. 기능 구현을 위한 script.js 부분 수정 및 작성
랭킹 보기 기능은 View 페이지가 로드될 때 직후 웹 크롤링을 진행하고 보이도록 (document).ready()로 설계되었다.
이전 테스트를 통해 show_comment() 부분과 비슷한 방법으로 show_ranking()을 작성한다.
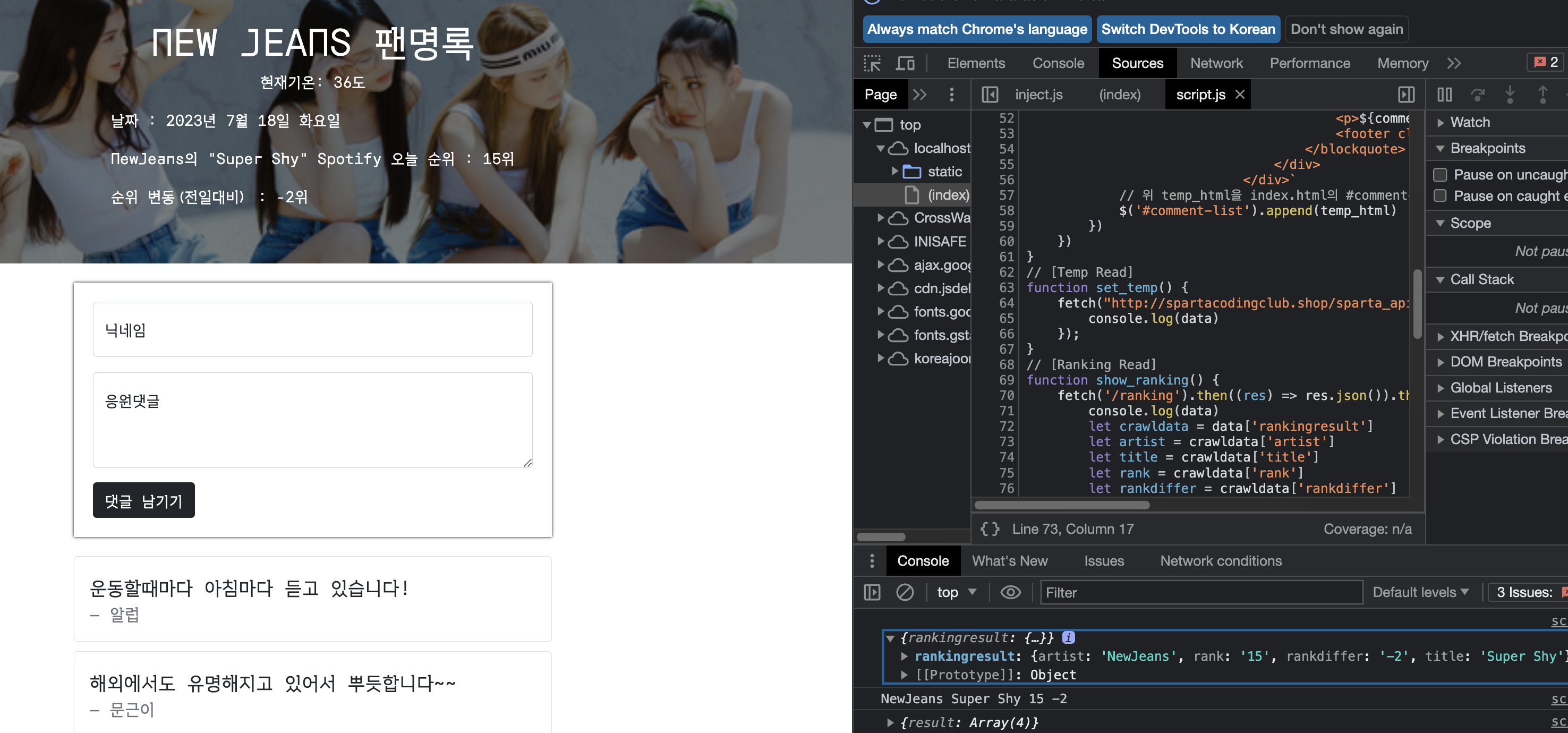
View 페이지인 index.html에서 id가 #artist, title, rank, rankdiff인 span태그에 가수, 노래, 순위, 순위 변동을 나타내는 값들이 입력되도록 작성해야 한다.

서버 시작 및 브라우저로 URL 입력하고 접속을 시작
- [기능 흐름 순서 1]
- URL 요청으로 View 페이지가 반환(load)되면
- JavaScript의 (document).ready()가 직후에 즉시 실행 됨
- 이후 내부 show_ranking() 함수 실행
- show_ranking() 내부 fetch()를 통해 '/guestbook' URL에 대한 GET 방식 요청 app.py로 이동
$(document).ready(function () {
set_temp();
show_comment();
show_ranking();
show_date();
});
...
// [Ranking Read]
function show_ranking() {
fetch('/ranking').then((res) => res.json()).then((data) => {app.py의 반환값 받은 이후(fetch() 이후. then() 절로 jsonify 변환 객체가 반환된 이후)
- [기능 흐름 순서 3]
- app.py 마지막에서 rankingdoc 객체를 jsonify()를 통해서 rankingresult Json 형식으로 변환된 데이터 를 반환 받는다.
- 해당 데이터는 첫 번째 then() 절의 res 인자값으로 들어감
- JavaScript로 다시 돌아와서 첫 번째 then()으로 들어간 res는 *response.json()에 의해 Promise 객체로 변환
- 해당 객체 데이터는 data라는 변수에 담겨있다.
- data를 리스트 형태의 crawldata 변수에 담고
- 'artist', 'title', 'rank', 'rankdiffer' key의 value값들이 artist, title, rannk, rankdiffer 변수에 담김
- 각 변수들을 HTML에 각 id위치의 내용을 empty()로 비워준 뒤 append()로 대체시켜 넣어줌
- (결과 View페이지에서는 웹 크롤링 된 곡 정보 및 순위 데이터들이 웹 페이지 Header에 기록됨)
// [Ranking Read]
function show_ranking() {
fetch('/ranking').then((res) => res.json()).then((data) => {
console.log(data)
// crawldata라는 리스트 객체 생성(promise인 data객체를 리스트로 변환)
let crawldata = data['rankingresult']
// 각 변수에 지정 데이터 담기
let artist = crawldata['artist']
let title = crawldata['title']
let rank = crawldata['rank']
let rankdiffer = crawldata['rankdiffer']
console.log(artist,title,rank,rankdiffer)
// HTML태그(id)에 각 데이터 비우기 후 삽입
$('#artist').empty().append(artist);
$('#title').empty().append(title);
$('#rank').empty().append(rank);
$('#rankdiff').empty().append(rankdiffer);
})
}5. 테스트
- Flask 서버가 실행 중인 상태
- 브라우저에서 localhost:5001 URL로 접속
- 웹 페이지 로드 직후( (document).ready() 즉시 실행 )
- document.ready에 포함된 show_ranking()실행되어 위 과정 진행
- 웹 크롤링 데이터 가 그대로 대체되어 변경 View 페이지에 나타남
- NewJeans의 "Super Shy" Spotify 오늘 순위 : 15위
- 순위 변동(전일대비) : -2위

해당 프로젝트는 아래 깃을 통해 업데이트되고 있습니다.
https://github.com/yzpocket/Flask_project_fan
GitHub - yzpocket/Flask_project_fan
Contribute to yzpocket/Flask_project_fan development by creating an account on GitHub.
github.com



