
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- beautifulsoup
- Crawling
- venv
- Project
- portfolio
- flaskframework
- Algorithm
- backend
- frontend
- synology
- PYTHON
- atlas
- flask
- NAS
- POST
- CRUD
- pymongo
- mongodb
- json
- CSS
- openapi
- javascript
- java
- github
- requests
- get
- OOP
- fetch
- mysql
- body
- Today
- Total
wisePocket
[Python] 파이썬 크롤링 with BeautifulSoup(bs4) - 1 본문
[Python] 파이썬 크롤링 with BeautifulSoup(bs4) - 1
ohnyong 2023. 7. 4. 23:28History
venv로 파이썬을 연습하고 있는 폴더의 가상 환경 구축을 완료
requests 라이브러리를 사용
BeautifulSoup 라이브러리 설치 및 사용
1. BeautifulSoup 라이브러리 설치
venv 가 활성화된 터미널에서 아래 커맨드로 BeautifulSoup란 라이브러리를 설치한다.
BeautifulSoup 라이브러리는 엄청 많은 HTML 코드 중에 우리가 원하는 특정 부분 을 빠르고 쉽게 필터링 해주는 라이브러리이다.
pip install bs4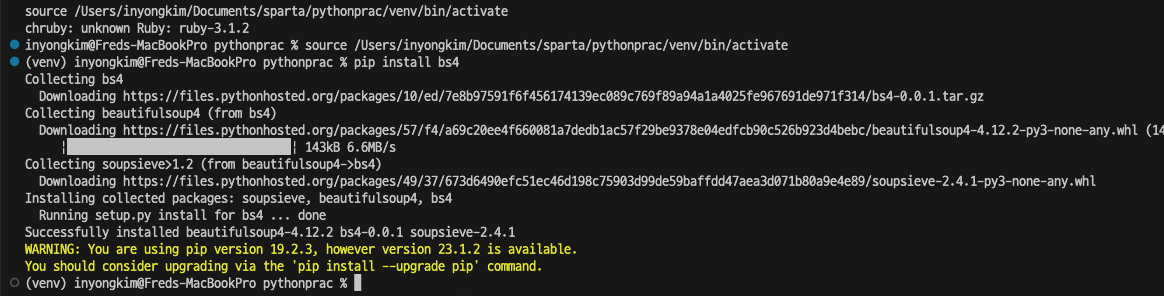
이같은 화면이 나타나고 금새 라이브러리 설치가 완료된다.
2. 라이브러리 임포트
라이브러리 설치가 완료되면 requests, 새로 설치한 BeautifulSoup 임포트
import requests
from bs4 import BeautifulSoup
3. 이제 크롤링을 시작하자
# 크롤링 = 웹페이지에서 어떤 데이터를 가져오는것
어떤 데이터인가가 중요하다.
특정 웹 페이지를 들어가면 개발자도구(F12)를 통해
해당 페이지의 소스코드를 확인 할 수 있다.
그 코드들 중 특정 태그나 특정 텍스트, 속성 등
원하는 데이터들을 "가져오는것" 을 크롤링이라 할 수 있다.
fetch도 마찬가지였지만
파이썬의 크롤링도 기본 코드가 있다.
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')import는 라이브러리를 사용하기위해서 작성된 것이고
URL은 크롤링 대상 웹페이지의 주소이다
headers
data
soup
부분은 무엇을 의미하는지 추가 공부가 필요하다.
우선 실습으로 테스트가 진행되는지부터 확인해보자.

예) 내가 원하는 데이터 영화 정보들이 "https://movie.daum.net/ranking/reservation" 링크에 있고
list_movieranking 클래스인 리스트 형태로 준비되어 있다.
다음과 같은 코드로 파이썬에서 크롤링을 준비하게 된다.
# 크롤링 = 웹페이지에서 어떤 데이터를 가져오는것
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 위 링크 페이지의 전체 HTML이 아웃풋 된다
print(soup)soup이라는 변수에 링크의 전체 html코드가 저장되고, print로 확인 할 수 있다.
4. 내가 원하는 데이터만 가져오기
soup의 select()를 통해 원하는 데이터 스코프를 지정 할 수 있다.
우선 내가 원하는 데이터(title)이 위치한 경로를 찾아낸다.
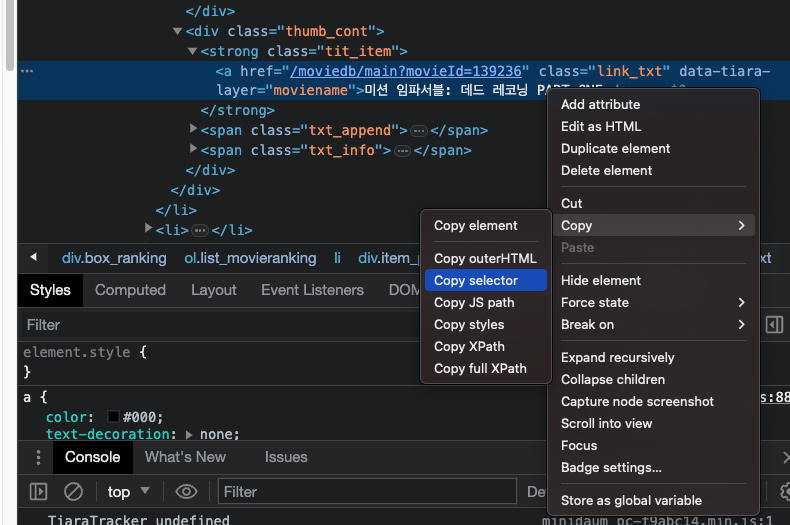
내가 추출하고 싶은 데이터는 영화의 title이고 코드 선택자 경로를 복사하면
#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a위와 같은 위치에 있다.
select_one을 사용하는 코드를 추가하고 위 경로를 입력해준다.
# 크롤링 = 웹페이지에서 어떤 데이터를 가져오는것
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 위 링크 페이지의 전체 HTML이 아웃풋 된다
# print(soup)
# BeautifulSoup 라이브러리는 엄청 많은 HTML 코드 중에 우리가 원하는 특정 부분 을 빠르고 쉽게 필터링 해주는 라이브러리이다.
# Title 데이터가 포함된 코드를 가져와보자
title = soup.select_one('#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a')
print(title)
# 그 중에서 텍스트만
print(title.text)
# 혹시나 그 중에서 속성만 가져오고 싶은 경우
# ( ['xxx'] -> dictionary 직접관계없다 bs개발자가 만든 문법이다.)
# print(title['href'])실행 결과 전체 HTML중에서 select_one(선택자)를 통해 해당 선택자에 속하는 아이템인
영화의 제목 부분만 1개 가져오는것을 확인 할 수 있다.

5. 응용
내가 원하던 값이 있었던 1개의 selector 경로 li:nth-child(1)가 아니라
그 상위 경로인 li 까지 지정해서
li를 포함한 태그들만 가져와본다.
# 내가원하는 데이터들이 리스트로 나열되어 있었다.
# 1개가 아니라 li를 포함한 전체 리스트들을 가져와보자
# 내가 원하는 값이 있었던 li:nth-child(1)가 아니라 li까지 스코프를 지정하자
titles = soup.select('#mainContent > div > div.box_ranking > ol > li')
print(titles)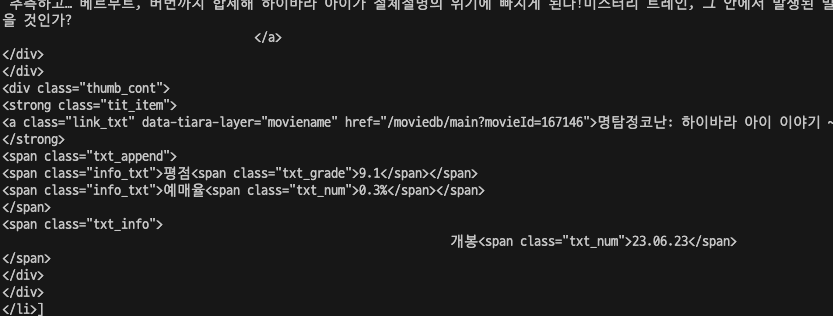
그 이후

link_txt라는 클래스의 <a> 태그들만 가져온다.
그리고 print(title.text)로 텍스트만 가져온다.
# 리스트 중에 반복문으로
# li 코드 내용 중에 클래스가 a class="link_txt"로 되어있는 태그부분만 가져오자
for li in titles:
title = li.select_one('.link_txt')
# print(title)
#그 중에 텍스트만 가져오자
print(title.text)
해당 스터디는 아래 깃을 통해 업데이트 되고 있습니다.
https://github.com/yzpocket/Sparta99training
GitHub - yzpocket/Sparta99training
Contribute to yzpocket/Sparta99training development by creating an account on GitHub.
github.com
'Python&Flask Tutorials, AWS EB > 3rd WEEK Python, Crawling, MongoDB' 카테고리의 다른 글
| [Database] DB 간단 개념 및 MongoDB Atlas 설정 (0) | 2023.07.05 |
|---|---|
| [Python] 파이썬 크롤링 with BeautifulSoup(bs4) - 2 (0) | 2023.07.04 |
| [Python] 파이썬 라이브러리 첫 사용 'requests' (0) | 2023.07.04 |
| [Python] 가상환경 venv의 필요성 (0) | 2023.07.04 |
| [Python] Python 사용 기초 실습 (0) | 2023.07.03 |



